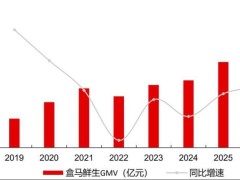
在人工智能算力发展的浪潮中,云端与终端的分化正日益显著。云端,万卡、十万卡集群已成为行业标配,头部应用日均消耗的Token量突破百万亿级,算力规模持续攀升。然而,当这些云端训练出的智能模型进入普通人的生活时,却往往沦为手机中需要联网等待数秒才能响应的对话框,算力与用户实际体验之间似乎横亘着一道难以逾越的鸿沟。
面对这一现状,一家国产GPU企业近日在发布会上推出多款端侧产品,试图打破算力与用户体验之间的壁垒。其发布的MTT AICUBE家庭智能中枢,以手掌大小的镁铝合金一体CNC机身亮相,内置自研"长江"SoC芯片,集成CPU、GPU、NPU、VPU异构计算单元,提供32GB/64GB统一内存和1TB起步的全闪存储空间。这款设备不仅支持4K视频输出和立体声交互,更能在本地运行大模型,实现语音控制、旅行规划、文件自动保存等60余项功能,高频工具调用成功率超过95%,任务执行速度较通用智能体提升7倍。
该企业的战略选择折射出GPU行业的深层分化。当前市场主要存在三条技术路线:以壁仞、天数智芯为代表的纯AI训练路线,专注提升算力密度而牺牲图形渲染能力;以景嘉微、砺算为代表的图形优先路线,在AI推理方面存在明显短板;沐曦则选择类似AMD的数据中心训推路线,图形产品线尚在研发阶段。这些路线虽各有商业逻辑,但都面临应用场景受限的挑战——纯AI芯片难以进入需要图形处理的消费级市场,图形芯片则无法满足AI算力需求。
摩尔线程自成立之初就选择了全功能GPU路线,其MUSA架构突破传统分类,在单一芯片上集成AI计算、图形渲染、科学计算、物理仿真和超高清视频处理五大能力。这种设计理念在端侧场景中展现出独特优势:当具身智能机器人需要同时处理AI决策和物理世界感知,当客厅设备需要驱动4K云游戏与实时数字人交互时,全功能架构能够满足这些复杂场景的并行计算需求。AICUBE的推出正是这种技术路线的实践验证,其通过紧凑的物理设计实现了数据中心级的多计算单元协调调度。
除家庭场景外,该企业同步推出了面向开发者的AIBOOK笔记本电脑和面向工业的E300模组。AIBOOK搭载基于Ubuntu改造的MTT AIOS系统,预装智能体开发平台,支持同时运行十几个AI Agent并对接90多个CLI工具接口,其虚拟化技术可实现Windows与Android系统的容器化运行。这些产品共同构建起从云端到终端的完整生态:云端显卡提供基础算力,边缘设备进行推理部署,终端产品实现交互落地,所有环节共享统一的MUSA架构。
在生态建设方面,摩尔线程已取得显著进展。其MUSA软件栈对国内主流大模型实现全面适配,DeepSeek、Qwen、Kimi等头部模型均可顺利运行,vLLM官方后端和SGLang主线代码已完成原生集成,PyTorch算子覆盖率达到100%。这种全栈兼容性为开发者提供了平滑的迁移路径,AIBOOK的推出则进一步降低了生态参与门槛——开发者可以在笔记本上直接完成模型训练的核心环节,构建起从开发、调试到部署的完整闭环。
从游戏显卡到仿真平台,从云端集群到端侧设备,摩尔线程的产品矩阵揭示着国产算力的发展逻辑:当算力渗透至数据中心、开发桌面、工业现场和家庭客厅等多元场景时,能够在每个入口建立技术壁垒的企业,将获得更持久的竞争优势。这种战略选择不仅体现在硬件产品的持续迭代上,更反映在生态建设的系统化布局中——通过统一架构降低迁移成本,通过全栈兼容减少适配门槛,最终实现国产算力在不同形态、不同场景中的全面落地。