代码大模型越来越卷,评估AI编程水平的“考卷”也被迫升级。12月5日,字节豆包大模型团队开源最新代码大模型评估基准FullStack Bench,在业界首次囊括编程全栈技术中超11类真实场景,覆盖16种编程语言,包含3374个问题,相比此前基准,可以更有效地评估大模型在现实世界中的代码开发能力。
代码评估基准是衡量大模型编程能力的标准工具,也是推动模型优化的关键驱动力。不过,当前的代码评估基准覆盖的应用类型和编程语言较为有限,难以反映真实世界中代码开发场景的多样性和复杂性。
比如,主流代码评测集Humaneval和MBPP中近80%数据只聚焦基础编程和高级编程问题;DS-1000中95%数据都集中于数据分析和机器学习任务,且仅对Python语言进行评测;xCodeeval虽覆盖多项任务,但基本局限于高级编程和数学领域。
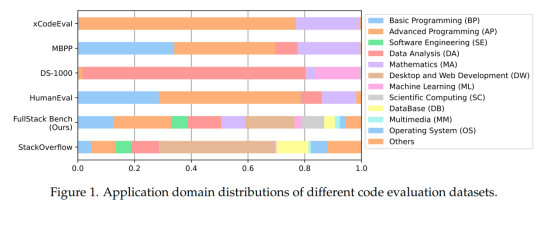
FullStack Bench数据覆盖超11种应用领域,远超当前主流代码评估基准
因此,字节豆包大模型团队与M-A-P开源社区联合提出FullStack Bench,一个专注于全栈编程和多语言编程的代码评估数据集。为囊括在真实全栈开发中涉及的各类应用场景,研究团队从全球最大的程序员技术问答社区Stack Overflow中随机抽取了50万个问题进行分析,筛选出占总问题数前88.1%的应用领域,并对其分布做了适当调整来保证每个领域的鲁棒性,最终形成了FullStack Bench关注的超过11种应用场景及分布比例。
FullStack Bench包含3374个问题,每个问题均包括题目描述、参考解决方案及单元测试用例,总计15168个单元测试。为保证评估准确性,问题内容均由相关领域的编程专家设计,并经AI和人工验证进行质量复核。在初始数据集构建后,团队根据主流代码大模型测试结果,按问题难度、模糊性和可解性对数据质量进行了交叉评估和进一步完善。
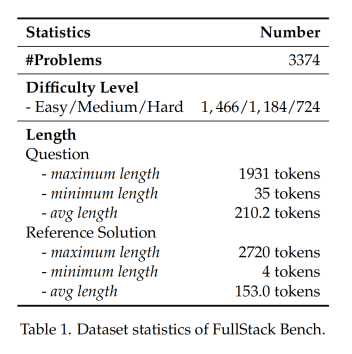
FullStack Bench数据集构成情况
为方便开发者对大模型代码能力进行系统性测试,豆包大模型团队还开源了一款高效的代码沙盒执行工具——SandboxFusion,用于评估来自不同语言的不同编程任务。除了FullStack Bench,SandboxFusion还兼容超过10种广泛使用的代码评估数据集,支持23种编程语言。开发者在单服务器上即可轻松部署SandboxFusion,也可直接在GitHub上进行体验。

发布评测基准及沙盒的同时,字节代码大模型也首次曝光。研究中,豆包大模型团队对全球20余款代码大模型及语言大模型的编程表现进行了评测(详见论文),其中包括未披露过的豆包代码大模型Doubao-Coder。
近半年,字节在代码大模型领域进展迅速,今年6月字节发布了由自研代码基座模型支撑的AI编程助手豆包MarsCode ,目前每月为用户贡献百万量级代码。
论文地址:https://arxiv.org/pdf/2412.00535v2
数据集开源地址:https://huggingface.co/datasets/ByteDance/FullStackBench
沙盒开源地址:https://github.com/bytedance/SandboxFusion
沙盒体验入口:https://bytedance.github.io/SandboxFusion/playground/datasets